When load testing our apps deployed in AWS cloud, we saw some really long, crazy timeouts on reads on all of the column families with a load of 500 odd threads for insert/update/delete using Datastax java driver v2.1.6.
Investigating Cassandra logs revealed:
“Scanned over 100000 tombstones; query aborted”
Tracing our cql queries, we saw tombstones information like the one below:
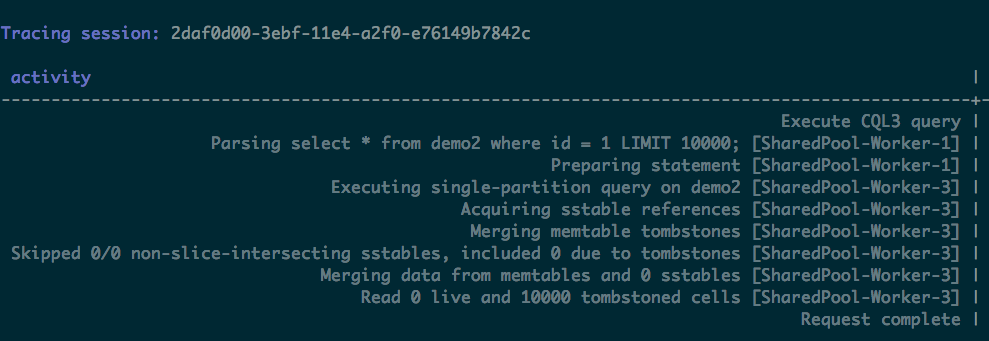
Because of these read latencies caused by tombstones, we did further research on how Cassandra deals with deletes.
Cassandra is a distributed system with immutable SSTables; deletes are done differently compared to a relational database. It stores all changes as immutable events. It can’t simply go back and mutate a record like a relational database would do.
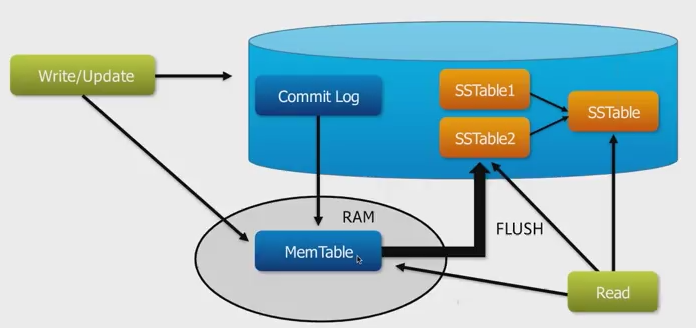
When writing to Cassandra, the following actions take place:
- The commit is logged to disk in a commit log entry and inserted into in-memory table
- Once the memtable reaches a limit (on entries), it is flushed to disk
- Entries from the memtable being flushed are appended to a current SSTable in the column family
- If compaction thresholds are reached, a compaction is run. Compaction is a maintenance process which re-organizes SSTables to optimize data structures on disk as well as reclaim unused space
What is a Tombstone?
A Tombstone is ‘dead data’ which is a record of Cassandra’s deletion. Deletes are performed by writing a ‘Tombstone’ to Cassandra like the other writes.
Also Cassandra marks TTL data with a tombstone after the requested amount of time has expired. Tombstones exist for a period of time defined by ‘gc_grace_seconds’ which can be defined at column family or cluster level. After data is marked with a tombstone, the data is automatically removed during the normal compaction process.
How can it become critical?
While performing a delete request, Cassandra will write that delete to all the replicas available at that time. If any node goes down at the time of delete, it waits until the node comes back. These tombstones will not be removed up to grace period defined and if the node fails to come up within the grace period, then we might see a scenario where deleted values would again become readable because a tombstone only made it to a limited set of replicas and then got cleaned up.

Too many tombstones can cause your query to fail; it is a safe guard to prevent against OOM and poor performance. We got to know from our load tests that 100000 plus tombstones were being scanned in our queries with the Cassandra v2.0.5.
Finally, we found the fix for it after contacting the Datastax support team with our test results and per their suggestion, we have upgraded our Cassandra from v2.0.5 to v2.1.14 and java driver to v3.0.1 to resolve these issues. Also we have been running the ‘node repair’ routinely on all the nodes to repair the inconsistencies across the replicas whenever a failure occurs.