Kafka is a publish-subscribe-based messaging system that is exchanging data between processes, applications and servers.
Messaging System:
A messaging system lets you send messages between processes, applications and servers.
Why we need Kafka:
- We need an effective messaging system or platform which can capture the big data generating sources and try to analyze and present all the rightful information to the rightful sources at the right time.
- It has built-in partitioning, replication, and fault-tolerance that makes it a good solution for large-scale message processing applications.
Kafka Components:
Kafka has 5 components in the cluster.
1) Zookeeeper:- It is primarily used as a configuration or registry type of index. It is a independent Apache project which kafka recommends and incorporates for its internal use, It is open source project which is highly available system. Primarily used for coordination and lookup service as a registry index in a distributed system. Primarily produces use zookeeper to identify the lead broker, so most of the times the producers interact with zookeeper to identify there are one two brokers in their cluster been set. Most of the producers interact with the zookeeper to identify the lead node/broker in the cluster
2) Broker:- Broker is nothing but a node/server in the cluster in which owns the topic
3) Topic:- It maintains the messages or bunch of the messages. These topics can be partitioned and distributed in multiple machines
4) Producer:- Producers are the ones which processes and publishes the incoming message or the activity data to the broker or to the cluster
5) Consumer:- Consumers are the processes which subscribe to the topics and pull all the msgs or the items or the data from the topics
Kafka Broker:
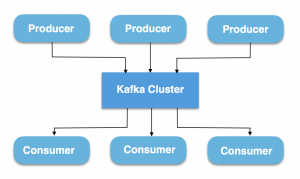
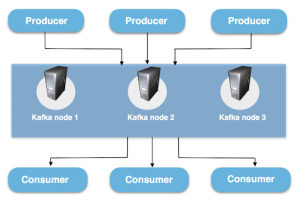
A Kafka cluster consists of one or more servers (Kafka brokers), which are running Kafka. Producers are processes that publish data (push messages) into Kafka topics within the broker. A consumer of topics pulls messages off a Kafka topic.
Kafka Topic:
A Topic is a category/feed name to which messages are stored and published. Messages are byte arrays that can store any object in any format. As said before, all Kafka messages are organized into topics. If you wish to send a message you send it to a specific topic and if you wish to read a message you read it from a specific topic. Producer applications write data to topics and consumer applications read from topics. Messages published to the cluster will stay in the cluster until a configurable retention period has passed by. Kafka retains all messages for a set amount of time and therefore, consumers are responsible to track their location.
Kafka topic partition:
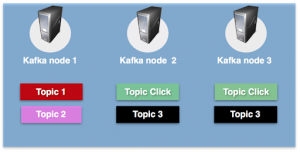
Kafka topics are divided into a number of partitions, which contains messages in an unchangeable sequence. Each message in a partition is assigned and identified by its unique offset. A topic can also have multiple partition logs like the click-topic has in the image. This allows for multiple consumers to read from a topic in parallel.

In Kafka, replication is implemented at the partition level. The redundant unit of a topic partition is called a replica. Each partition usually has one or more replicas meaning that partitions contain messages that are replicated over a few Kafka brokers in the cluster. As we can see in the pictures – the click-topic is replicated to Kafka node 2 and Kafka node 3.
Note: It’s possible for the producer to attach a key to the messages and tell which partition the message should go to. All messages with the same key will arrive at the same partition.
Partitions allow you to parallelize a topic by splitting the data in a particular topic across multiple brokers.
Every partition (replica) has one server acting as a leader and the rest of them as followers. The leader replica handles all read-write requests for the specific partition and the followers replicate the leader. If the leader server fails, one of the follower servers become the leader by default. When a producer publishes a message to a partition in a topic, it is forwarded to its leader. The leader appends the message to its commit log and increments its message offset. Kafka only exposes a message to a consumer after it has been committed and each piece of data that comes in will be stacked on the cluster.